A.I. Αναγνωρίζει τι Βλέπουμε “Διαβάζοντας το Μυαλό μας”
Τι βλέπει το μυαλό μας όταν κοιτάμε αυτή την εικόνα;

Χρησιμοποιώντας ένα σύστημα fMRI μπορούμε να “σκανάρουμε” έναν ανθρώπινο εγκέφαλο με μη επεμβατικό τρόπο και να δούμε την δραστηριότητα των νευρώνων του εγκεφάλου την ώρα που κοιτάμε μια εικόνα.
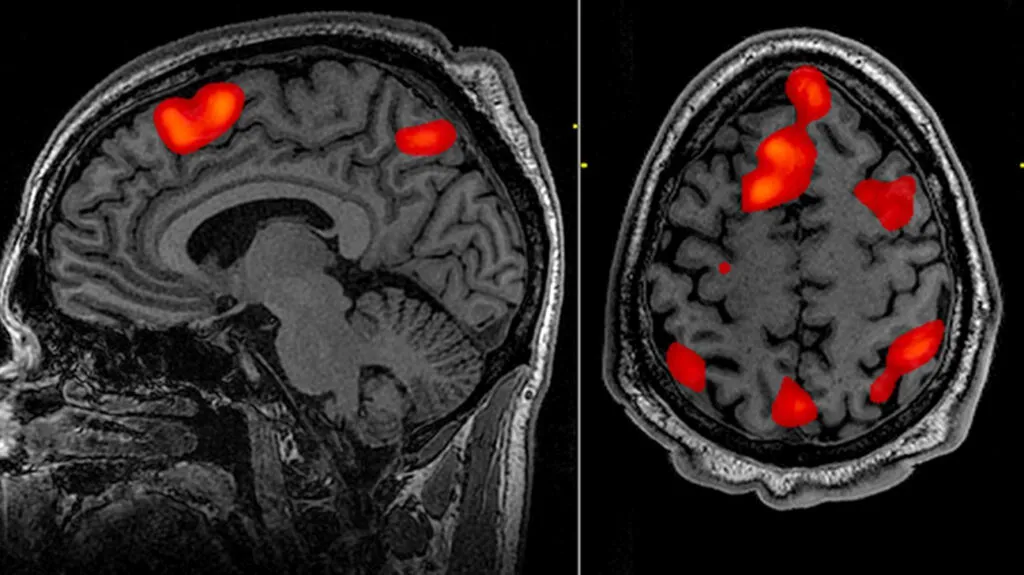
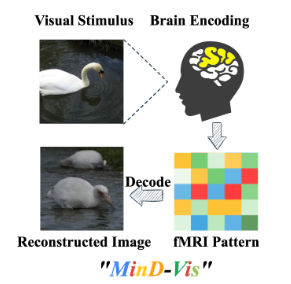
Αν μπορούσαμε τώρα να κάνουμε την αντίστροφη διαδικασία και να ανακατασκευάσουμε την αρχική εικόνα, αποκωδικοποιώντας την fMRI απεικόνιση, ουσιαστικά θα ήταν σαν να διαβάζουμε το μυαλό μας.
Η Είδηση
Μία νέα προδημοσίευση μας δείχνει πως είναι εφικτό να ανακατασκευάσουμε εικόνες υψηλής ανάλυσης “διαβάζοντας” fMRI απεικονίσεις.
Οι ερευνητές παρουσιάζουν πως με την τεχνική που ονόμασαν MinD-Vis, δεν ανασυνθέτουν απλά την αρχική εικόνα, αλλά φαίνεται πως μπορούν να ερμηνεύσουν νοηματικά το αντικείμενο που απεικονίζεται και να καταλάβουν τα σημαντικότερα χαρακτηριστικά της εικόνας. Έτσι η εικόνα που παράγεται μπορεί να μην είναι η ίδια πίξελ προς πίξελ, αλλά θα διατηρεί το νόημα της αρχικής εικόνας.
Στο παρακάτω παράδειγμα βλέπετε τις αρχικές εικόνες και τις εικόνες που δημιούργησε η MinD-Vis αποκωδικοποιώντας την fMRI απεικόνιση.

Γιατί Έχει Σημασία
Η λειτουργική μαγνητική τομογραφία εγκεφάλου, ή αλλιώς fMRI, μας επιτρέπει να μελετήσουμε την εγκεφαλική δραστηριότητα, μετρώντας μεταβολές της ροής του αίματος που σχετίζονται με την ενεργοποίηση των νευρώνων του εγκεφάλου.
Δεν είναι η πρώτη φορά που ερευνητές προσπαθούν να διαβάσουν fMRI απεικονίσεις για να δημιουργήσουν την αρχική εικόνα. Όμως πρόκειται για μία πολύ σύνθετη διαδικασία και τα μέχρι τώρα αποτελέσματα έδιναν είτε θολές εικόνες χαμηλής ευκρίνειας, είτε εικόνες που δεν αποτυπώνουν καλά το νόημα της αρχικής εικόνας.

Ένα σημαντικό εμπόδιο στην έρευνα είναι τα ίδια τα δεδομένα.
Πολλές από τις υπάρχουσες τεχνικές βασίζονται σε τεχνικές μηχανικής μάθησης με επίβλεψη. Αυτό σημαίνει ότι για την εκπαίδευση ενός τέτοιου συστήματος απαιτούνται πολλές fMRI απεικονίσεις σε συνδυασμό με την αρχική εικόνα που παρατηρήθηκε όταν λήφθηκε το δείγμα. Δυστυχώς όμως δεν υπάρχουν ακόμα πολλά ζεύγη εικόνων – fMRI απεικονίσεων στα διαθέσιμα σετ δεδομένων.
Ένα ακόμα πρόβλημα είναι πως η ενεργοποίηση των νευρώνων ποικίλει από άνθρωπο σε άνθρωπο. Αυτό σημαίνει πως η ίδια εικόνα μπορεί να δημιουργήσει διαφορετικά ερεθίσματα και να αναπαριστάται με διαφορετικό τρόπο σε fMRI απεικονίσεις διαφορετικών ανθρώπων.
Η MinD-Vis συνδυάζει δύο τεχνικές που την βοηθούν να ξεπεράσει αυτούς τους προβληματισμούς σε μεγάλο βαθμό.
Πως Λειτουργει
Στο πρώτο στάδιο εκπαιδεύεται ένα τεχνητό νευρωνικό δίκτυο με πάρα πολλές εικόνες από fMRI απεικονίσεις χωρίς επίβλεψη. Με αυτή την τεχνική (Sparse-Coded Masked Brain Modeling (SC-MBM)) εφαρμόζεται μία μάσκα που καλύπτει έως και το 75% της απεικόνισης και το δίκτυο μαθαίνει να συμπληρώνει τα κενά. Με αυτόν τον τρόπο, το δίκτυο μπορεί να μην ξέρει σε τι εικόνες αντιστοιχούν οι fMRI απεικονίσεις, αλλά μαθαίνει την αλληλοσυσχέτιση των γειτονικών νευρώνων στην κάθε περίπτωση.

Στο τέλος γίνεται μία επιπλέον εκπαίδευση του μοντέλου με λίγα μόνο ζεύγη εικόνων-fMRI και έτσι γεφυρώνεται το κενό μεταξύ των νευρωνικών απεικονίσεων και των χαρακτηριστικών των εικόνων.
Στο δεύτερο στάδιο χρησιμοποιείται ένα μοντέλο τύπου Diffusion (DC-LDM) που λαμβάνει σαν είσοδο απεικονίσεις fMRI και προσπαθεί να συνθέσει μία πραγματική εικόνα στην έξοδο.
Τα μοντέλα τύπου diffusion είναι στοχαστικά μοντέλα και λειτουργούν σαν μαρκοβιανές αλυσίδες. Ξεκινάνε με τυχαίο θόρυβο και αφαιρώντας σταδιακά τον θόρυβο διαμορφώνεται και σχηματίζεται μια εικόνα.
Τον τελευταίο καιρό έχουμε δει μοντέλα diffusion να χρησιμοποιούνται ευρέως σε εφαρμογές δημιουργίας εικόνων από κείμενο. Πρόκειται για την ίδια τεχνική, μόνο που αντί να προσπαθούμε να αναγνωρίσουμε τα σημαντικά μέρη μίας πρότασης για να δημιουργήσουμε μία εικόνα, προσπαθούμε να αναγνωρίσουμε μία συσχέτιση νευρώνων που αποτυπώνονται σε μία fMRI απεικόνιση.
Οι Σκέψεις μου Πάνω στο Θέμα
Τα αποτελέσματα μιας τέτοιας έρευνας μπορούν να μας δώσουν χρήσιμες πληροφορίες για τον τρόπο που λειτουργεί η όραση και ο εγκέφαλος μας.
Από ερευνητικής σκοπιάς βρίσκω εξαιρετικά ενδιαφέρουσα την μεταφορά γνώσης από ένα επιστημονικό πεδίο σε ένα άλλο.
Πρόσφατα είδαμε τις εντυπωσιακές δυνατότητες των μοντέλων diffusion στην δημιουργία εικόνων και μέσα σε σύντομο χρονικό διάστημα έχουμε την χρήση τους για την ανακατασκευή εικόνων από απεικονίσεις fMRI.
Πηγαίνοντας μερικά χρόνια μπροστά, αν στο μέλλον έχουμε BMI (Brain-Machine Interface) συσκευές που μας επιτρέπουν να λαμβάνουμε σήματα από τον εγκέφαλο μας σε πραγματικό χρόνο, η ικανότητα ανάλυσης και αναγνώρισης των εικόνων που λαμβάνονται θα δώσουν μια εντελώς νέα διάσταση στον τρόπο που αλληλεπιδρούμε με τους υπολογιστές.
Το σίγουρο είναι ότι το μέλλον προβλέπεται εντυπωσιακό!

