Τον τελευταίο καιρό έχουμε δει εκπληκτικές εφαρμογές τεχνητής νοημοσύνης στο πεδίο της παραγωγής και της κατανόησης λόγου. Μεγάλα γλωσσικά μοντέλα, όπως το GPT-3 ή το GPT-j, φαίνεται πως μπορούν να αναγνωρίσουν τα σημαντικά μέρη σε μία πρόταση και να δημιουργήσουν προτάσεις όπου διατηρείται η συνοχή σε εντυπωσιακό βαθμό.
Βασιζόμενοι στην λογική αυτών των γλωσσικών μοντέλων, είδαμε ότι αν εκπαιδεύσουμε μοντέλα με ζεύγη εικόνων-κειμένων μπορούμε να “μάθουμε” σε ένα A.I. μοντέλο να αναγνωρίζει τους συσχετισμούς μεταξύ μίας εικόνας και της περιγραφής της. Ως αποτέλεσμα, βλέπουμε όλο και περισσότερες εφαρμογές ικανές να περιγράψουν με κείμενο το περιεχόμενο μιας εικόνας, ή ακόμα και να δημιουργήσουν μια εντελώς νέα εικόνα λαμβάνοντας σαν είσοδο μία περιγραφή σε απλό κείμενο!
Μέσα σε λιγότερο από 2 χρόνια έχουμε δει εντυπωσιακή εξέλιξη στα μοντέλα παραγωγής εικόνας από κείμενο. Μέσα σε λίγους μήνες, η αντίληψη μας για τις ικανότητες αυτών των μοντέλων άλλαξε ριζικά! Πριν λίγο καιρό η ιδέα της αυτόματης παραγωγής εικόνων με μία περιγραφή σε φυσική γλώσσα φάνταζε εξωπραγματική, όμως τώρα η τεχνολογία έχει ήδη ενσωματωθεί σε εφαρμογές που χρησιμοποιούμε καθημερινά όπως ένα απλό φίλτρο στο TikTok.
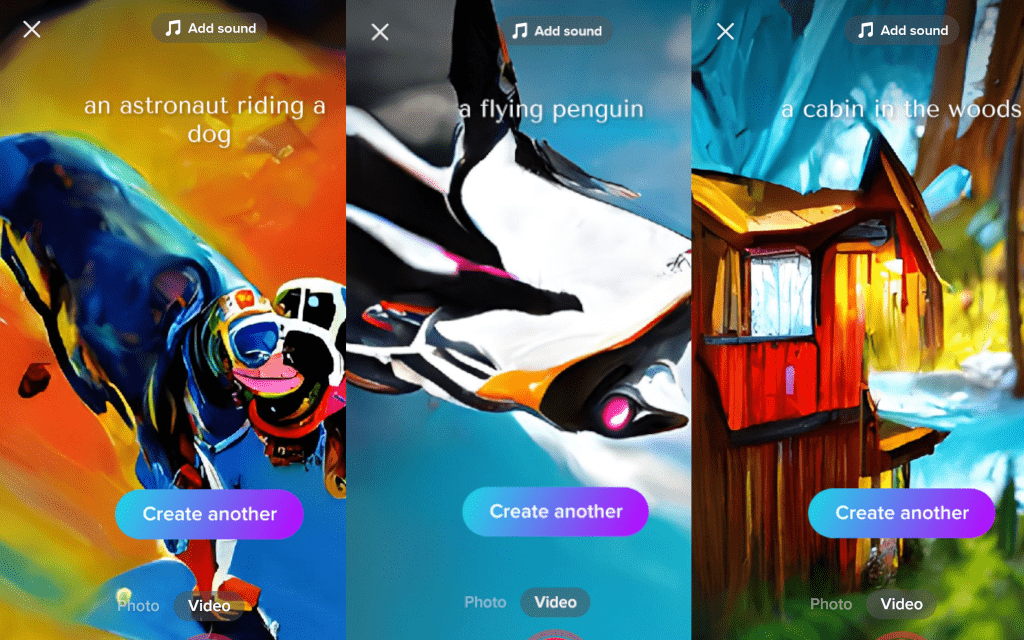
Σε αυτό το άρθρο θα γίνει μία σύντομη παρουσίαση των δημοφιλέστερων μοντέλων παραγωγής εικόνων από κείμενο και θα δούμε πως περάσαμε από το DALL-E της OpenAI στο ανοιχτού κώδικα Stable Diffusion!
DALL-E
Τον Ιανουάριο του 2021 η OpenAI δημοσίευσε το μοντέλο DALL-E. Το DALL-E βασίζεται στο γλωσσικό μοντέλο GPT-3 και εκπαιδεύτηκε σε ένα πολύ μεγάλο σετ δεδομένων με ζευγάρια εικόνων – περιγραφών. Με αυτόν τον τρόπο το DALL-E μπορούσε να αναγνωρίσει χαρακτηριστικά μίας πρότασης όπως το σχήμα ή το χρώμα ενός αντικειμένου, το όνομα κάποιου ζώου, το στυλ μίας εικόνας και άλλα.
Ως αποτέλεσμα το DALL-E μπορούσε να παράγει εικόνες με περιεχόμενο πολύ κοντά στην περιγραφή που έδινε ο εκάστοτε χρήστης.
Επιπλέον με την βοήθεια ενός άλλου εργαλείου του CLIP (Contrastive Language–Image Pre-training), τα αποτελέσματα του DALL-E βαθμολογούνται και ταξινομούνται ανάλογα με το πόσο κοντά είναι η παραγόμενη εικόνα στην περιγραφή που δόθηκε. Έτσι το τελικό αποτέλεσμα που παίρνουμε από τον συνδυασμό των μοντέλων DALL-E και CLIP είναι μία αρκετά ακριβής απεικόνιση της περιγραφής του χρήστη.
Παράδειγμα:
Περιγραφή: Μία πολυθρόνα στο σχήμα ενός αβοκάντο

Περιγραφή: Μία ζωγραφιά από ένα capybara που κάθεται σε μία πεδιάδα στο ηλιοβασίλεμα στο στυλ του Van Gogh

VQGAN & CLIP
Τον Ιούνιο του 2021 μία έρευνα παρουσίασε μία νέα πρόταση για την δημιουργία εικόνων υψηλής ανάλυσης από κείμενο. Με το μοντέλο VQGAN (Vector Quantised Generative Adversarial Network) οι συγγραφείς δείχνουν πως με τον συνδυασμό συνελικτικών νευρωνικών δικτύων και δικτύων transformers, μπορούμε να παράγουμε εικόνες υψηλής ανάλυσης διατηρώντας την πιστή αντιστοίχιση της περιγραφής με την εικόνα που παράγεται.
Σε αντίθεση με την OpenAI και το DALL-E, οι ερευνητές έδωσαν στην δημοσιότητα το εκπαιδευμένο μοντέλο VQGAN και έτσι πολύ γρήγορα η διαδικτυακή κοινότητα κατακλίστηκε από εντυπωσιακά έργα τέχνης φτιαγμένα από τεχνητή νοημοσύνη. Μάλιστα, σε μία από τις εφαρμογές που δημιουργήθηκαν, συνδυάστηκε το VQGAN με το μοντέλο CLIP, ώστε να αξιολογούνται συνεχώς οι εικόνες που παράγονται σταδιακά από το VQGAN και να οδηγούμαστε σταδιακά σε μία πιο πιστή αναπαράσταση.
Τα αποτελέσματα του VQGAN τα είδαμε και στο σχετικό βίντεο στο Tech to me About it.

CLIP Guided Diffusion
Τον ίδιο μήνα το 2021 η OpenAI δημοσίευσε μια μελετη για το πώς τα μοντέλα τύπου diffusion μπορούν να γίνουν πολύ καλύτερα στην παραγωγή εικόνων απ’ ότι τα επικρατέστερα μοντέλα τύπου GAN.
Τα μοντέλα τύπου diffusion είναι στοχαστικά μοντέλα και λειτουργούν σαν μαρκοβιανές αλυσίδες. Ξεκινάνε με το να προσθέτουν σταδιακά θόρυβο σε μια εικόνα και στην συνέχεια μαθαίνουν να αντιστρέφουν την διαδικασία σε έναν πεπερασμένο αριθμό βημάτων. Κατά συνέπεια, ένα εκπαιδευμένο μοντέλο τύπου diffusion ξεκινάει με τυχαίο θόρυβο και αφαιρώντας σταδιακά τον θόρυβο διαμορφώνει και σχηματίζει μια εικόνα.

Λίγο αργότερα η καλλιτέχνιδα Katherine Crowson (@RiversHaveWings) συνδίασε το guided diffusion μοντέλο της OpenAI με το CLIP δίνοντας μας άλλη μία εντυπωσιακή εφαρμογή ανοικτού κώδικα.

DALL-E mini / Craiyon
Τον Απρίλιο του 2022 κυκλοφόρησε η πρώτη επίσημη έκδοση της εφαρμογής DALL-E mini που αργότερα μετονομάστηκε σε Craiyon.
Τα αποτελέσματα του DALL-E ενέπνευσαν αρκετές ομάδες προγραμματισμών και καλλιτεχνών. Όμως η OpenAI προσέφερε μόνο περιορισμένη beta πρόσβαση στο μοντέλο της. Έτσι λοιπόν οι Boris Dayma και Pedro Cuenca επιχείρησαν να αναπαράγουν την λογική του DALL-E σε μία μικρότερη αρχιτεκτονική νευρωνικών δικτύων.
Το μοντέλο DALL-E mini έδειξε εντυπωσιακά αποτελέσματα αναλογικά με το μέγεθος του μοντέλου. Το DALL-E mini είναι 27 φορές μικρότερο από το DALL-E και εκπαιδεύτηκε σε πολύ λιγότερα δεδομένα, σε πολύ μικρότερο χρονικό διάστημα. Συνεπώς, οι εικόνες που παράγει υστερούν σε ποιότητα, όμως οι ικανότητες του μοντέλου παραμένουν εντυπωσιακές.
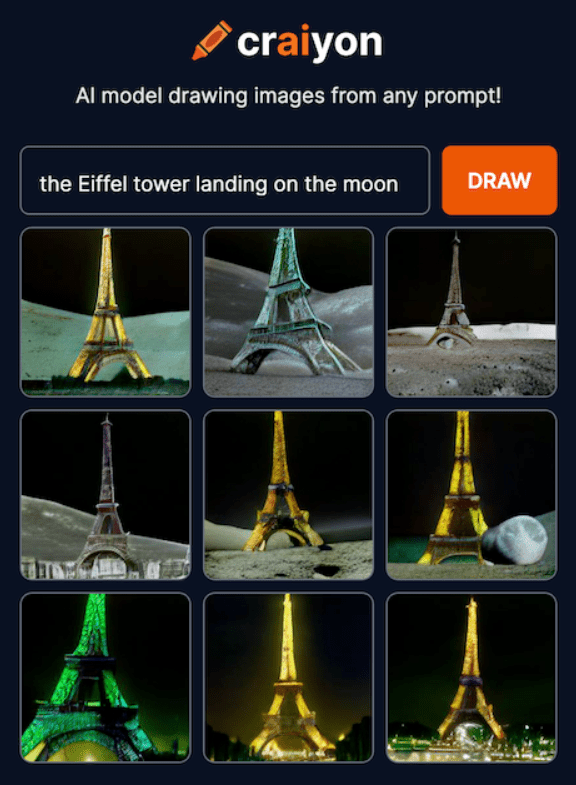
Μπορείτε να δοκιμάσετε δωρεάν την εφαρμογή στην σελίδα https://www.craiyon.com
MidJourney
Τον Απρίλιο του 2022 ξεκίνησε επίσης η δοκιμαστική λειτουργία της εφαρμογής MidJourney.
Η ομάδα πίσω από το MidJourney είναι ένα μικρό ερευνητικό εργαστήριο. Παρ’ όλο που δεν έχουν δώσει το μοντέλο τους στην δημοσιότητα, αυτή την στιγμή η εφαρμογή τους βρίσκεται σε ανοιχτή beta έκδοση και μπορεί οποιοσδήποτε να παράγει τις δικές του εικόνες μέσω ενός API που λειτουργεί με την μορφή ενός Discord bot.
Οι εικόνες του MidJourney είναι πολύ εντυπωσιακές και δίνουν μία καλλιτεχνική αίσθηση παραπάνω απ’ ότι έχουμε συνηθίσει στις άλλες εφαρμογές.

Μπορείτε να αποκτήσετε πρόσβαση στο API αποδέχοντας την πρόσκληση στον Discord server του MidJourney.
DALL-E 2
Τον Απρίλιο του 2022 είχαμε επίσης την δημοσίευση της έρευνας γύρω από το DALL-E 2 από την OpenAI. Το DALL-E 2 βασίζεται και αυτό σε μοντέλα τύπου diffusion σε συνεργασία με το CLIP, αλλά οι εικόνες που παράγει είναι μακράν οι πιο καθαρές, πιο υψηλής ποιότητας και πιο ακριβείς από κάθε άλλη εφαρμογή που είχε κυκλοφορήσει μέχρι εκείνη την στιγμή.

Δυστυχώς η OpenAI ακολούθησε την ίδια πρακτική και μέχρι τώρα έχει δώσει πρόσβαση στην δοκιμαστική λειτουργία του μοντέλου σε ένα πολύ περιορισμένο πλήθος χρηστών.
Imagen
Τον Μάιο του 2022 μπήκε δυναμικά και η Google στο παιχνίδι της παραγωγής εικόνων με A.I. εργαλεία δημοσιεύοντας τη μελέτη του μοντέλου Imagen. Το Imagen είναι και αυτό βασισμένο σε μοντέλα τύπου diffusion και σκοπός του είναι η παραγωγή φωτορεαλιστικών εικόνων υψηλής ευκρίνειας. Οι συγγραφείς της μελέτης παρατήρησαν πως χρησιμοποιώντας ένα μεγάλο αποκλειστικά γλωσσικό μοντέλο στην είσοδο, καταφέρνουν να παράγουν ακόμα πιο πιστές αναπαραστάσεις στην έξοδο του diffusion μοντέλου. Η Google δεν έχει δημοσιεύσει ακόμα το μοντέλο ή κάποιο API για πρόσβαση στην εφαρμογή, αλλά οι εικόνες που δημοσιεύουν είναι πραγματικά εντυπωσιακές και συγκρίσιμες με αυτές του DALL-E 2.

Stable Diffusion
Τα τελευταία νέα στον χώρο του της αυτόματης παραγωγής εικόνων από τεχνητή νοημοσύνη αφορούν αναμφισβήτητα το Stable Diffusion! Οι δυνατότητες του Stable Diffusion είναι εφάμιλλες των DALL-E 2 και Imagen, όμως το Stable Diffusion ξεχωρίζει για 2 βασικούς λόγους. Ο πρώτος είναι ότι πετυχαίνει μικρότερους χρόνους εκτέλεσης χάρη στην τεχνική που χρησιμοποιεί, και ο δεύτερος, και ίσως σημαντικότερος για την κοινότητα, είναι ότι είναι ανοιχτού κώδικα και το εκπαιδευμένο μοντέλο έχει δημοσιευθεί ελεύθερο για όλους τους χρήστες.

Το Stable Diffusion είναι δημιούργημα της ερευνητικής ομάδας CompVis και δημοσιεύτηκε τον Ιούνιο του 2022. Λίγες εβδομάδες αργότερα κυκλοφόρησε και το εκπαιδευμένο μοντέλο στην κοινότητα και εκεί φάνηκε η δύναμη που έχει το λογισμικό ανοιχτού κώδικα. Μέσα σε λίγες μόνο μέρες κυκλοφόρησαν δωρεάν εφαρμογές ανοιχτού κώδικα που επιτρέπουν στον καθένα να τρέξει παράγει εικόνες με τα Stable Diffusion.
Από online πλατφόρμες όπως το Ηuggingface ή το Google Colab μέχρι και γραφικό περιβάλλον που μπορεί να να εγκαταστήσει και να τρέξει κάποιος τοπικά στον υπολογιστή του.
Το Stable Diffusion χρησιμοποιεί παρόμοια λογική με το Imagen. Βασίζεται σε μία ειδική κατηγορία μοντέλων diffusion και χρησιμοποιεί το CLIP για την κωδικοποίηση του κειμένου εισόδου. Ο τύπος του μοντέλου που χρησιμοποιείται, ονομάζεται Latent Diffusion Model (LDM) και αυτός είναι ο βασικός λόγος που πετυχαίνει μικρότερο χρόνο εκτέλεσης.
Latent Space ή Λανθάνων Χώρος ονομάζεται το σημείο όπου βρίσκονται κωδικοποιημένες ή αν θέλετε συμπιεσμένες μορφές των αρχικών εικόνων της εκπαίδευσης ενός μοντέλου.
Ένα μοντέλό LDM βασίζεται σε αυτές τις συμπιεσμένες εικόνες αντί για τις αρχικές, συγκριτικά τεράστιες αναπαραστάσεις των εικόνων.
Στο πρώτο άκουσμα μιας τεχνητής νοημοσύνης που δημιουργεί σύνθετες εικόνες που δεν έχει “δει” ποτέ, κάποιος μπορεί να σκεφτεί πως απειλείται η ανθρώπινη τέχνη και η δουλειά των καλλιτεχνών. Όμως από τις πρώτες δοκιμές μπορούμε ήδη να δούμε πως καλλιτέχνες επιλέγουν να δημιουργήσουν μαζί με την τεχνητή νοημοσύνη!
Μια εικόνα από ΤΝ μπορεί να αποτελέσει έμπνευση για την περαιτέρω δημιουργία από τον άνθρωπο καλλιτέχνη. Ή θα μπορούσε να λειτουργήσει σαν ένα εργαλείο για ταχύτερο storyboarding. Την γραφική αναπαράσταση, δηλαδή, των βασικών σκηνών μιας αφήγησης ή ενός animation.
Η ταχύτητα που αναπτύσσονται τα μοντέλα δημιουργίας εικόνων από ΤΝ και η ταχύτητα που ενσωματώνονται σε διάφορες εμπορικές εφαρμογές ανοιχτού κώδικα είναι πραγματικά εντυπωσιακή. Βρισκόμαστε μόλις στο ξεκίνημα αυτού του εντυπωσιακού επιστημονικού κλάδου και πραγματικά ανυπομονώ να δω τι θα γίνει στην συνέχεια.
Μου φαίνεται απίστευτο ότι σε λίγο καιρό οι άνθρωποι θα θεωρούν δεδομένο το γεγονός ότι ο υπολογιστής ή το κινητό τους μπορεί να τους δημιουργεί σύνθετες αναπαραστάσεις με μία απλή περιγραφή κειμένου. Κάτι που σήμερα μοιάζει σχεδόν μαγικό, πολύ σύντομα θα μας κάνει την ίδια εντύπωση που κάνει ένα Google search σήμερα. Αυτή είναι η μαγεία της τεχνολογικής εξέλιξης!
Παραδείγματα εφαρμογών που βασίζονται στο Stable Diffusion:
Σύγκριση αποτελεσμάτων MidJourney – DALLE-2 – Stable Diffusion:

